标签搜索


搜索到
9
篇与
网络技术
的结果
-
 在Linux系统下批量压缩图片 第一步:安装支持处理文件类型:JPG、JPEGsudo apt install jpegoptim支持处理文件类型:PNG, BMP, GIF, PNM or TIFF,这个优化效率太低了,速度奇慢无比sudo apt install optipng其中2款工具的具体使用参数如下JPEGOPTIM 名称 jpegoptim - 用于优化/压缩JPEG/JFIF文件。 概要 jpegoptim [ options ] [ filenames ] 描述 pegoptim用于优化/压缩jpeg文件。项目支持无损优化,这是基于对Huffman表的优化。所谓的“有损”优化除了优化之外。可以指定图像质量的上限。 选项 选项可以是传统的POSIX一个字母选项,也可以是。GNU风格长选项。 POSIX风格选项以一个“-”开头,而GNU的长选项以''--'开头。 jpegoptim提供的选项如下: -d<path>, --dest=<path> //设置备选目标目录,以便保存优化。文件(默认是覆盖原始文件)。 //请注意,不变的文件不会被添加到目标目录。 //这意味着如果源文件不能被压缩,就不会有文件。在目标路径中创建。 -f, --force //强制优化,即使结果大于。原始文件。 -h, --help //显示简短的使用信息并退出。 -m<quality>, --max=<quality> //设置最大图像质量因子(禁用无损优化)。mization模式是默认启用的。 //设置这个选项会降低使用更高版本保存的源文件的质量。而那些已经有较低质量的文件。设置将使用无损优化进行压缩。 -n, --noaction //不要真的优化文件,只需打印结果。 -S<size>, --size=<size> //尝试优化文件大小(禁用了无损优化mizaiont模式)。目标尺寸指定KB(1 N)或百分比(1% - 99%)的原始文件的大小。 -T<treshold>, --threshold=<treshold> //如果压缩增益低于阈值(%),则保持文件不变。传输安全有效值为:0 - 100 -o, --overwrite //覆盖目标文件,即使它存在(使用D选项)。 -p, --preserve //保存文件修改时间。 -q, --quiet //安静模式。 -t, --totals //处理完所有文件后打印总计。 -v, --verbose //启用详细模式(积极聊天). --all-normal //强制所有输出文件为非逐行扫描。可以用来转换所有输入文件的渐进式JPEG当使用--force选项。 --all-progressive //强制所有输出文件都是渐进的。可以将所有输入文件正常(非连续)当使用--force选项的JPEG文件。 --strip-all //去除所有(Comment & Exif)从输出文件删除标记。(注!默认情况下只有Comment & Exif标记保存,其他一切都是丢弃) --strip-com //从输出文件中删除Comment(COM)标记。 --strip-exif //从输出文件中删除标记。 --strip-iptc //从输出文件中删除IPTC标记。 --strip-icc //将ICC配置文件从输出文件中删除。 Bugs: 当使用size选项时,结果文件并不总是精确的请求大小。解决方法是重新运行jpegoptim在同一文件又往往会导致文件大小接近目标。OPTIPNG命令手册 NAME OptiPNG−优化便携式网络图形文件 SYNOPSIS optipng [−? | −h | −help] optipng [options...] files... DESCRIPTION OptiPNG程序将尝试优化PNG文件,即将其大小减小到最小值。失去语义信息。此外,该程序还应执行一套辅助功能。完整性检查、元数据恢复和pixmapto - png转换。 优化尝试不能保证成功。有效的PNG文件不能被这个程序优化,通常是原封不动的,它们的大小不会增长。用户可以请求重写此默认行为。 FILES 输入文件是用PNG格式(本机格式)或外部格式编码的光栅图像文件。当前支持的外部格式是GIF、BMP、PNM和TIFF。 OptiPNG处理命令行中给出的每个图像文件如下: −如果是PNG格式的图像: 试图优化给定文件的位置。如果优化是成功的,或者选择−力被激活,其优化的版本替换原来的文件。原始文件备份,如果选择−保持启用。 −如果图像是一个外部格式: 创建给定文件的优化PNG版本。输出文件名由原始文件名和PNG扩展名组成。 现有的文件不会被覆盖,除非该选项启用−clobber OPTIONS 通用选项 −?, −h, −help //显示选项的完整摘要。 −backup, −keep //对修改后的文件进行备份。 −clobber //覆盖现有的输出和备份文件。在这个选项,如果选择−backup 未启用,覆盖旧的备份文件的删除。 −dir directory //将输出文件写入目录。 −fix //启用错误恢复。此选项对有效的输入文件没有影响。 //程序将花费大量的精力在不增加输出文件大小的情况下尽可能地恢复尽可能多的数据,但不能保证成功。该程序可能会增加文件的大小,例如,重建丢失的关键数据。在此选项下,完整性应优先于文件大小。 //当此选项未被使用时,无效的输入文件将被未处理。 −force //强制编写新的输出文件。 //此选项覆盖程序的决定不写这样的文件,例如当PNG输入数字签名(使用dsig),或当PNG输出变得大于PNG输入。 −log file //将消息记录到文件。出于安全原因,文件必须有扩展名。此选项已被废弃,最终将被删除。使用shell重定向。 −out file //将输出文件写入文件。命令行必须只包含一个输入文件。 −preserve //保存(文件属性的文件访问时间邮票,在人权等)适用。 −quiet, −silent // 在安静的运行模式。 −simulate //运行模拟模式:执行测试,但不创建输出文件。 −v //启用该选项 −verbose and −version. −verbose //在详细模式运行。 −version //显示版权,版本和建立信息。 −− //选择开关停止解析。 PNG编码和优化选项。 −o level //选择优化级别 //优化level0enables一组优化操作,需要最少的努力。将不会有任何变化的图像的属性一样,比特深度或颜色的类型,并没有再压缩现有IDAT数据流。 //优化level1enables单IDAT压缩试验。试验选择的是什么,OptiPNG认为这可能是最有效的。 //优化level2和更高的使多个IDAT压缩试验;此选项的行为和默认值可能会在不同的程序版本中发生更改。使用选项−H看到有关您的特定版本。 −f filters //选择PNG增量过滤器。 //过滤器的参数被指定为一个rangeset(例如−F0−5),和默认的过滤器值取决于设置的选项−O.优化水平过滤器的值0, 1, 2,3和4显示静态滤波,和对应的标准PNG过滤代码(无,左,上,平均和Paeth,分别)。滤波值5表明自适应滤波,其作用是通过libpng的定义(3)用optipng。 −full //制作一份关于IDAT的完整报告。这种选择可能会减缓试验的速度。 −i type //选择交错类型(0−1)。 //如果交错式0被选择,输出图像应非隔行扫描(即progressivescanned)。如果交错式1被选择,输出图像应交错使用adam7方法。默认情况下,输出应具有相同的类型作为输入接口。 −nb //不要应用位深度还原。 −nc //不要使用颜色类型还原。 −np //不应用调色板还原。 −nx //不适用任何无损图像还原:启用选项−nb,-nc控和−−np。 −nz //不记录IDAT数据流 −zc levels //选择IDAT压缩中使用的zlib压缩级别。 −zm levels //选择IDAT压缩中使用的zlib内存级别。 −zs strategies //选择在IDAT压缩中使用的zlib压缩策略。 −zw size //选择zlib窗口大小(32 k,16 k、8 k、4 k,2 k,1 k,512256)中使用IDAT压缩。 Editing options −snip //从多图像、动画或视频文件中删除一个图像。 −strip objects //从PNG文件中删除元数据对象。首先我们把手机连接电脑上,找到图片目录,进行操作。# 查询大于2M的图片文件 # 查询总数量 :215535个文件 find -type f -size +2M -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\|png\|PNG\)" | wc -l # 文件大小统计,这个统计 find -type f -size +2M -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\|png\|PNG\)" | xargs du -ach # 上面文件大小统计的命令不太准确,后面因统计不太准确,所以找到了以下的命令,可以直接计算出文件的大小、文件的数量 # 查询大于2M 的所有图片数量与文件大小 # 总数量:339586个 # 总大小:1068.79G # 平均大小:3.2M find . -size +2048 -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\|png\|PNG\)" -exec ls -l {} \; |awk 'BEGIN{count=0;size=0;} \ {count = count + 1; size = size + $5/1024/1024;} \ END{print "Total count " count; \ print "Total Size " size/1024 " GB" ; \ print "Avg Size " size / count "MB"; \ print "—"}'压缩1、首先对jpg、jpeg格式的图片进行压缩测试# 对2M以上文件进行压缩,压缩品质为60,-p为保留原文件修改时间,-t为压缩完成后统计输出压缩率 find . -size +2048 -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\)" | xargs jpegoptim -m60 -p -t 以上操作会在原文件基础上进行压缩覆盖,并且保留原文件修改时间,不会覆盖为新的时间,如果有需要是要将压缩后的文件放到新的文件夹中,原文件保留的话可以使用以下命令# 文件压缩后会输出到new 文件夹,注意需要手动先新建文件夹 find . -size +2048 -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\)" | xargs jpegoptim -m60 -p -t -d new 经压缩测试总空间为59G的文件夹(包含不符合压缩条件的文件共计),压缩时间约2小时左右,共释放内存29G,压缩率为74% 左右,其中以1022G为基准进行压缩,具体压缩品质与压缩率对照如下。2、对png格式进行压缩默认压缩如下,其他参数如上述参数描述,可以视情况进行增加find -name '*.png' | xargs optipng经测试,这个压缩速度极慢无比,不知道是不是我使用方法不当,而且压缩率很低,一个10861KB的png图片,压缩之后为10858KB。有人说是因为optipng会对比各种优化方案,选择最优的方案所以比较慢。鉴于此,且系统中的png图片占相对比较小相对于jpg的1个T左右,总共9个G,故此次不对png图片进行压缩。3、如果有需要,压缩png图片的话,可以使用ImageMagick 使用这个包,然后使用以下命令进行压缩,压缩率较高,可以压缩任意格式的图片,但是速度相对于jpegoptim有点慢# ImageMagick sudo install ImageMagick # png格式的图片压缩使用optimpng 压缩效率太低了 ,使用ImageMagick测试可行,但是效率一般,150M大小10个文件左右需要35秒左右,不过可以压缩大文件,且不区分文件类型都可以压缩, 如100M以上的jpg、png都可以文件 find ./ -regex '.*\(png\|PNG\)' -size +2M -exec convert -quality 60 {} {} \;注意测试过程中发现有几点问题需要注意的,此处做一个汇总1、尽量使用root账号进行压缩,否则原拥有者为root,使用其他账号压缩之后会变更为登录账号,且压缩过程中输出详情信息会提示错误,就是因为无法变更拥有者为root,不过文件可以正常压缩。2、压缩之前尽量先对文件进行备份,避免出现意向不到的问题3、测试过程中,曾经对一个119M的jpg文件进行压缩,但是却报错了,开始以为是jpegoptim对于太大的文件压缩不支持,后续使用参数-v, --verbose //启用详细模式(积极聊天)发现错误信息为,提示:Not a JPEG file: starts with 0x89 0x50,由此可以发现,这个jpg文件为假的jpg,有可能是该文件上传之前为png或者其他格式,经过手动修改变成了jpg格式,所以造成无法处理,针对此类文件只能进行单独处理了,比如使用上述的ImageMagick进行压缩,可以将119M的文件压缩至7M左右。总结因为本身对于Linux系统不太熟悉,所以在实际过程中还是走了不少的弯路的,还在最终提供了完整的解决方案,记录学习。后续实际操作过程中发现,使用jpegoptim 后台执行,中间不知道为中断了,而且可能是系统之前对上传的图片进行了重命名,所以造成了大量图片无法进行压缩,报错信息为:Not a JPEG file: starts with 0x89 0x50,综合考虑,切换方案,使用ImageMagick后台执行,为避免报错还要加上这个>/dev/null 2>/dev/null,否则会报nohup: ignoring input and appending output to ‘nohup.out’nohup find ./ -regex '.*\(jpg\|jpeg\|JPG\|JPEG\)' -size +2M -exec convert -quality 60 {} {} \; >/dev/null 2>/dev/null &最终压缩内存800G左右,耗时18小时左右,之前压缩测试时这个ImageMagick速度不快,没想到实操过程中速度可观,且压缩品质也不错。如何使用 FFmpeg 减少视频大小视频压缩sudo ffmpeg -i 3.mp4 -vcodec libx265 -crf 25 33.mp4没有通用的方法来减小视频文件的大小,因为各种文件类型的创建并不相同。在本教程中,我们将使用 x265 编解码器。x265 编解码器,它是一个免费的库,用于视频编码为 H.254/MPEG-H HEVC 的压缩格式。CRF使用 0 到 51 之间的数字。恒定速率因子(CRF)是 x264 和 x265 编码的默认质量设置。值越高,压缩率越高,值越高这可能会导致质量损失。————————————————版权声明:本文为CSDN博主「ao123056」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/ao123056/article/details/123479736
在Linux系统下批量压缩图片 第一步:安装支持处理文件类型:JPG、JPEGsudo apt install jpegoptim支持处理文件类型:PNG, BMP, GIF, PNM or TIFF,这个优化效率太低了,速度奇慢无比sudo apt install optipng其中2款工具的具体使用参数如下JPEGOPTIM 名称 jpegoptim - 用于优化/压缩JPEG/JFIF文件。 概要 jpegoptim [ options ] [ filenames ] 描述 pegoptim用于优化/压缩jpeg文件。项目支持无损优化,这是基于对Huffman表的优化。所谓的“有损”优化除了优化之外。可以指定图像质量的上限。 选项 选项可以是传统的POSIX一个字母选项,也可以是。GNU风格长选项。 POSIX风格选项以一个“-”开头,而GNU的长选项以''--'开头。 jpegoptim提供的选项如下: -d<path>, --dest=<path> //设置备选目标目录,以便保存优化。文件(默认是覆盖原始文件)。 //请注意,不变的文件不会被添加到目标目录。 //这意味着如果源文件不能被压缩,就不会有文件。在目标路径中创建。 -f, --force //强制优化,即使结果大于。原始文件。 -h, --help //显示简短的使用信息并退出。 -m<quality>, --max=<quality> //设置最大图像质量因子(禁用无损优化)。mization模式是默认启用的。 //设置这个选项会降低使用更高版本保存的源文件的质量。而那些已经有较低质量的文件。设置将使用无损优化进行压缩。 -n, --noaction //不要真的优化文件,只需打印结果。 -S<size>, --size=<size> //尝试优化文件大小(禁用了无损优化mizaiont模式)。目标尺寸指定KB(1 N)或百分比(1% - 99%)的原始文件的大小。 -T<treshold>, --threshold=<treshold> //如果压缩增益低于阈值(%),则保持文件不变。传输安全有效值为:0 - 100 -o, --overwrite //覆盖目标文件,即使它存在(使用D选项)。 -p, --preserve //保存文件修改时间。 -q, --quiet //安静模式。 -t, --totals //处理完所有文件后打印总计。 -v, --verbose //启用详细模式(积极聊天). --all-normal //强制所有输出文件为非逐行扫描。可以用来转换所有输入文件的渐进式JPEG当使用--force选项。 --all-progressive //强制所有输出文件都是渐进的。可以将所有输入文件正常(非连续)当使用--force选项的JPEG文件。 --strip-all //去除所有(Comment & Exif)从输出文件删除标记。(注!默认情况下只有Comment & Exif标记保存,其他一切都是丢弃) --strip-com //从输出文件中删除Comment(COM)标记。 --strip-exif //从输出文件中删除标记。 --strip-iptc //从输出文件中删除IPTC标记。 --strip-icc //将ICC配置文件从输出文件中删除。 Bugs: 当使用size选项时,结果文件并不总是精确的请求大小。解决方法是重新运行jpegoptim在同一文件又往往会导致文件大小接近目标。OPTIPNG命令手册 NAME OptiPNG−优化便携式网络图形文件 SYNOPSIS optipng [−? | −h | −help] optipng [options...] files... DESCRIPTION OptiPNG程序将尝试优化PNG文件,即将其大小减小到最小值。失去语义信息。此外,该程序还应执行一套辅助功能。完整性检查、元数据恢复和pixmapto - png转换。 优化尝试不能保证成功。有效的PNG文件不能被这个程序优化,通常是原封不动的,它们的大小不会增长。用户可以请求重写此默认行为。 FILES 输入文件是用PNG格式(本机格式)或外部格式编码的光栅图像文件。当前支持的外部格式是GIF、BMP、PNM和TIFF。 OptiPNG处理命令行中给出的每个图像文件如下: −如果是PNG格式的图像: 试图优化给定文件的位置。如果优化是成功的,或者选择−力被激活,其优化的版本替换原来的文件。原始文件备份,如果选择−保持启用。 −如果图像是一个外部格式: 创建给定文件的优化PNG版本。输出文件名由原始文件名和PNG扩展名组成。 现有的文件不会被覆盖,除非该选项启用−clobber OPTIONS 通用选项 −?, −h, −help //显示选项的完整摘要。 −backup, −keep //对修改后的文件进行备份。 −clobber //覆盖现有的输出和备份文件。在这个选项,如果选择−backup 未启用,覆盖旧的备份文件的删除。 −dir directory //将输出文件写入目录。 −fix //启用错误恢复。此选项对有效的输入文件没有影响。 //程序将花费大量的精力在不增加输出文件大小的情况下尽可能地恢复尽可能多的数据,但不能保证成功。该程序可能会增加文件的大小,例如,重建丢失的关键数据。在此选项下,完整性应优先于文件大小。 //当此选项未被使用时,无效的输入文件将被未处理。 −force //强制编写新的输出文件。 //此选项覆盖程序的决定不写这样的文件,例如当PNG输入数字签名(使用dsig),或当PNG输出变得大于PNG输入。 −log file //将消息记录到文件。出于安全原因,文件必须有扩展名。此选项已被废弃,最终将被删除。使用shell重定向。 −out file //将输出文件写入文件。命令行必须只包含一个输入文件。 −preserve //保存(文件属性的文件访问时间邮票,在人权等)适用。 −quiet, −silent // 在安静的运行模式。 −simulate //运行模拟模式:执行测试,但不创建输出文件。 −v //启用该选项 −verbose and −version. −verbose //在详细模式运行。 −version //显示版权,版本和建立信息。 −− //选择开关停止解析。 PNG编码和优化选项。 −o level //选择优化级别 //优化level0enables一组优化操作,需要最少的努力。将不会有任何变化的图像的属性一样,比特深度或颜色的类型,并没有再压缩现有IDAT数据流。 //优化level1enables单IDAT压缩试验。试验选择的是什么,OptiPNG认为这可能是最有效的。 //优化level2和更高的使多个IDAT压缩试验;此选项的行为和默认值可能会在不同的程序版本中发生更改。使用选项−H看到有关您的特定版本。 −f filters //选择PNG增量过滤器。 //过滤器的参数被指定为一个rangeset(例如−F0−5),和默认的过滤器值取决于设置的选项−O.优化水平过滤器的值0, 1, 2,3和4显示静态滤波,和对应的标准PNG过滤代码(无,左,上,平均和Paeth,分别)。滤波值5表明自适应滤波,其作用是通过libpng的定义(3)用optipng。 −full //制作一份关于IDAT的完整报告。这种选择可能会减缓试验的速度。 −i type //选择交错类型(0−1)。 //如果交错式0被选择,输出图像应非隔行扫描(即progressivescanned)。如果交错式1被选择,输出图像应交错使用adam7方法。默认情况下,输出应具有相同的类型作为输入接口。 −nb //不要应用位深度还原。 −nc //不要使用颜色类型还原。 −np //不应用调色板还原。 −nx //不适用任何无损图像还原:启用选项−nb,-nc控和−−np。 −nz //不记录IDAT数据流 −zc levels //选择IDAT压缩中使用的zlib压缩级别。 −zm levels //选择IDAT压缩中使用的zlib内存级别。 −zs strategies //选择在IDAT压缩中使用的zlib压缩策略。 −zw size //选择zlib窗口大小(32 k,16 k、8 k、4 k,2 k,1 k,512256)中使用IDAT压缩。 Editing options −snip //从多图像、动画或视频文件中删除一个图像。 −strip objects //从PNG文件中删除元数据对象。首先我们把手机连接电脑上,找到图片目录,进行操作。# 查询大于2M的图片文件 # 查询总数量 :215535个文件 find -type f -size +2M -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\|png\|PNG\)" | wc -l # 文件大小统计,这个统计 find -type f -size +2M -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\|png\|PNG\)" | xargs du -ach # 上面文件大小统计的命令不太准确,后面因统计不太准确,所以找到了以下的命令,可以直接计算出文件的大小、文件的数量 # 查询大于2M 的所有图片数量与文件大小 # 总数量:339586个 # 总大小:1068.79G # 平均大小:3.2M find . -size +2048 -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\|png\|PNG\)" -exec ls -l {} \; |awk 'BEGIN{count=0;size=0;} \ {count = count + 1; size = size + $5/1024/1024;} \ END{print "Total count " count; \ print "Total Size " size/1024 " GB" ; \ print "Avg Size " size / count "MB"; \ print "—"}'压缩1、首先对jpg、jpeg格式的图片进行压缩测试# 对2M以上文件进行压缩,压缩品质为60,-p为保留原文件修改时间,-t为压缩完成后统计输出压缩率 find . -size +2048 -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\)" | xargs jpegoptim -m60 -p -t 以上操作会在原文件基础上进行压缩覆盖,并且保留原文件修改时间,不会覆盖为新的时间,如果有需要是要将压缩后的文件放到新的文件夹中,原文件保留的话可以使用以下命令# 文件压缩后会输出到new 文件夹,注意需要手动先新建文件夹 find . -size +2048 -regex ".*\.\(jpg\|JPG\|jpeg\|JPEG\)" | xargs jpegoptim -m60 -p -t -d new 经压缩测试总空间为59G的文件夹(包含不符合压缩条件的文件共计),压缩时间约2小时左右,共释放内存29G,压缩率为74% 左右,其中以1022G为基准进行压缩,具体压缩品质与压缩率对照如下。2、对png格式进行压缩默认压缩如下,其他参数如上述参数描述,可以视情况进行增加find -name '*.png' | xargs optipng经测试,这个压缩速度极慢无比,不知道是不是我使用方法不当,而且压缩率很低,一个10861KB的png图片,压缩之后为10858KB。有人说是因为optipng会对比各种优化方案,选择最优的方案所以比较慢。鉴于此,且系统中的png图片占相对比较小相对于jpg的1个T左右,总共9个G,故此次不对png图片进行压缩。3、如果有需要,压缩png图片的话,可以使用ImageMagick 使用这个包,然后使用以下命令进行压缩,压缩率较高,可以压缩任意格式的图片,但是速度相对于jpegoptim有点慢# ImageMagick sudo install ImageMagick # png格式的图片压缩使用optimpng 压缩效率太低了 ,使用ImageMagick测试可行,但是效率一般,150M大小10个文件左右需要35秒左右,不过可以压缩大文件,且不区分文件类型都可以压缩, 如100M以上的jpg、png都可以文件 find ./ -regex '.*\(png\|PNG\)' -size +2M -exec convert -quality 60 {} {} \;注意测试过程中发现有几点问题需要注意的,此处做一个汇总1、尽量使用root账号进行压缩,否则原拥有者为root,使用其他账号压缩之后会变更为登录账号,且压缩过程中输出详情信息会提示错误,就是因为无法变更拥有者为root,不过文件可以正常压缩。2、压缩之前尽量先对文件进行备份,避免出现意向不到的问题3、测试过程中,曾经对一个119M的jpg文件进行压缩,但是却报错了,开始以为是jpegoptim对于太大的文件压缩不支持,后续使用参数-v, --verbose //启用详细模式(积极聊天)发现错误信息为,提示:Not a JPEG file: starts with 0x89 0x50,由此可以发现,这个jpg文件为假的jpg,有可能是该文件上传之前为png或者其他格式,经过手动修改变成了jpg格式,所以造成无法处理,针对此类文件只能进行单独处理了,比如使用上述的ImageMagick进行压缩,可以将119M的文件压缩至7M左右。总结因为本身对于Linux系统不太熟悉,所以在实际过程中还是走了不少的弯路的,还在最终提供了完整的解决方案,记录学习。后续实际操作过程中发现,使用jpegoptim 后台执行,中间不知道为中断了,而且可能是系统之前对上传的图片进行了重命名,所以造成了大量图片无法进行压缩,报错信息为:Not a JPEG file: starts with 0x89 0x50,综合考虑,切换方案,使用ImageMagick后台执行,为避免报错还要加上这个>/dev/null 2>/dev/null,否则会报nohup: ignoring input and appending output to ‘nohup.out’nohup find ./ -regex '.*\(jpg\|jpeg\|JPG\|JPEG\)' -size +2M -exec convert -quality 60 {} {} \; >/dev/null 2>/dev/null &最终压缩内存800G左右,耗时18小时左右,之前压缩测试时这个ImageMagick速度不快,没想到实操过程中速度可观,且压缩品质也不错。如何使用 FFmpeg 减少视频大小视频压缩sudo ffmpeg -i 3.mp4 -vcodec libx265 -crf 25 33.mp4没有通用的方法来减小视频文件的大小,因为各种文件类型的创建并不相同。在本教程中,我们将使用 x265 编解码器。x265 编解码器,它是一个免费的库,用于视频编码为 H.254/MPEG-H HEVC 的压缩格式。CRF使用 0 到 51 之间的数字。恒定速率因子(CRF)是 x264 和 x265 编码的默认质量设置。值越高,压缩率越高,值越高这可能会导致质量损失。————————————————版权声明:本文为CSDN博主「ao123056」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/ao123056/article/details/123479736 -
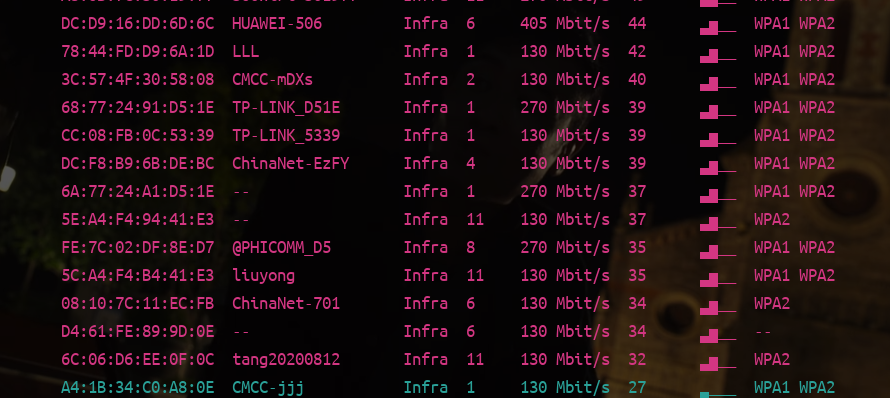
关于在Linux终端下连接wifi 在Linux终端环境下面使用命令行连接wifi首先如果我们的Linux没有安装 network-manager安装 sudo apt install network-manager 重启 sudo service network-manager restart 检测附近wifi热点 sudo nmcli dev wifi连接wifi sudo nmcli dev wifi connect "pang" password "123456789" 重启network-manager如果出现Device 'wlan0' successfully 就表示连接成上了热点。
-
关于合宙air780E在linux使用上网 准备工具1.Linux设备1台 2.数据线1条 3.合宙Air780E1个 4.小白一个序言在2021年11月中旬的时候,在合宙粉丝群里有个大佬分享的购物链接,合宙Air780E 9块9包邮一个(现在淘宝39元一个),当时我并没太注意,就想买来一个玩玩拿来玩玩后,感觉linux系统不太适用,网上查了一大堆资料也没办法实现上网。。。。过了2个月后,今天,我看见了这台吃灰了的产品,就拿来玩玩,再查了下资料,发现可以用哈,发现用处挺多的,记录此篇博客。 简介 首先,我们先了解以下什么是合宙720E,RNDIS是什么?RNDIS是指Remote NDIS,基于USB实现RNDIS实际上就是TCP/IP over USB,就是在USB设备上跑TCP/IP,让USB设备看上去像一块网卡。从而使Windows /Linux可以通过 USB 设备连接网络。目前linux大部分发行版本都已经默认支持RNDIS驱动了,只要通过USB连接Air780E模块就可以直接用了,模块开机后就会在linux设备端看到新的网卡通过lsusb查看模块的vid与pid,分别是19d1和0001Air780E与Air720的驱动修改方式一致,都需要添加对应的Vendor ID和Product ID。 常见问题 一般情况下,不是特别精简的linux 已经支持rndis 功能,如果插上合宙的4G 模块,但是不能上网的话,需要注意以下几点。1. 能否检测到rndis 设备在命令行中输入 dmesg ,如此出现 rndis_host 1-1:1.0 eth1 这样的打印,则证明已经识别到了,(如果没有,可能是硬件问题,也可能是linux 真的不支持.此时查看ifconfig ,如果没有出现 rndis_host 1-1:1.0 eth1 中的 eth1 ,(我这里是enx2089846a96ab)则发送ifconfig -a ,此时发现有eth1 但是 没有ip 地址,发送 udhcpc -i eth1 出现地址后,即可使用此网卡进行上网如果你的Linux没有udhcpc话,可以通过命令 sudo apt install udhcpc 安装。 结束语 现在,我们的配置就完了,可以正常上网了,没错就这么简单,我把这个放在树莓派上使用,摆脱了网线和WIFI的束缚,可以随身携带到学校和农村使用了。
-
linux中Mysql8.0使用说明 apt install mysql-server-8.01. 但是MySQL8.0 安装完成后出现无法远程连接的现象,这是因为MySQL8.0只支持 localhost 访问,我们必须设置一下才可以远程访问。 2. 命令登入服务器mysql 3.执行下面语句添加权限 use mysql;select host, user, authentication_string, plugin from user;查看user表的root用户Host字段是localhost,说明root用户只能本地登录,现在把他改成远程登录update user set host='%' where user='root'; 4.刷新权限 所有操作后,应执行FLUSH PRIVILEGES;5.检查服务器端口用到的其他命令 netstat -an | grep 3306 查看3306端口 ps -ef | grep mysqld 查看mysqld进程 sudo service mysqld start 启动mysql服务 sudo service mysqld stop 停止mysql服务 sudo ufw enable 允许防火墙 sudo ufw disable 禁止防火墙配置文件如下 vim /etc/mysql/mysql.d/my.cnf*[client] port = 3306socket = /tmp/mysql.sock[mysqld]user = mysql --- 表示MySQL的管理用户port = 3306 --- 端口socket = /tmp/mysql.sock -- 启动的sock文件log-bin = /data/mysql-binbasedir = /usr/local/mysqldatadir = /data/pid-file = /data/mysql.piduser = mysqlbind-address = 0.0.0.0server-id = 1 #表示是本机的序号为1,一般来讲就是master的意思skip-name-resolve禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求skip-networkingback_log = 600MySQL能有的连接数量。当主要MySQL线程在一个很短时间内得到非常多的连接请求,这就起作用,然后主线程花些时间(尽管很短)检查连接并且启动一个新线程。back_log值指出在MySQL暂时停止回答新请求之前的短时间内多少个请求可以被存在堆栈中。如果期望在一个短时间内有很多连接,你需要增加它。也就是说,如果MySQL的连接数据达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源。另外,这值(back_log)限于您的操作系统对到来的TCP/IP连接的侦听队列的大小。你的操作系统在这个队列大小上有它自己的限制(可以检查你的OS文档找出这个变量的最大值),试图设定back_log高于你的操作系统的限制将是无效的。max_connections = 1000MySQL的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,所以要适当调整该值,不能盲目提高设值。可以过'conn%'通配符查看当前状态的连接数量,以定夺该值的大小。max_connect_errors = 6000对于同一主机,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST。open_files_limit = 65535MySQL打开的文件描述符限制,默认最小1024;当open_files_limit没有被配置的时候,比较max_connections*5和ulimit -n的值,哪个大用哪个,当open_file_limit被配置的时候,比较open_files_limit和max_connections*5的值,哪个大用哪个。table_open_cache = 128MySQL每打开一个表,都会读入一些数据到table_open_cache缓存中,当MySQL在这个缓存中找不到相应信息时,才会去磁盘上读取。默认值64假定系统有200个并发连接,则需将此参数设置为200*N(N为每个连接所需的文件描述符数目);当把table_open_cache设置为很大时,如果系统处理不了那么多文件描述符,那么就会出现客户端失效,连接不上max_allowed_packet = 4M接受的数据包大小;增加该变量的值十分安全,这是因为仅当需要时才会分配额外内存。例如,仅当你发出长查询或MySQLd必须返回大的结果行时MySQLd才会分配更多内存。该变量之所以取较小默认值是一种预防措施,以捕获客户端和服务器之间的错误信息包,并确保不会因偶然使用大的信息包而导致内存溢出。binlog_cache_size = 1M一个事务,在没有提交的时候,产生的日志,记录到Cache中;等到事务提交需要提交的时候,则把日志持久化到磁盘。默认binlog_cache_size大小32Kmax_heap_table_size = 8M定义了用户可以创建的内存表(memory table)的大小。这个值用来计算内存表的最大行数值。这个变量支持动态改变tmp_table_size = 16MMySQL的heap(堆积)表缓冲大小。所有联合在一个DML指令内完成,并且大多数联合甚至可以不用临时表即可以完成。大多数临时表是基于内存的(HEAP)表。具有大的记录长度的临时表 (所有列的长度的和)或包含BLOB列的表存储在硬盘上。如果某个内部heap(堆积)表大小超过tmp_table_size,MySQL可以根据需要自动将内存中的heap表改为基于硬盘的MyISAM表。还可以通过设置tmp_table_size选项来增加临时表的大小。也就是说,如果调高该值,MySQL同时将增加heap表的大小,可达到提高联接查询速度的效果read_buffer_size = 2MMySQL读入缓冲区大小。对表进行顺序扫描的请求将分配一个读入缓冲区,MySQL会为它分配一段内存缓冲区。read_buffer_size变量控制这一缓冲区的大小。如果对表的顺序扫描请求非常频繁,并且你认为频繁扫描进行得太慢,可以通过增加该变量值以及内存缓冲区大小提高其性能read_rnd_buffer_size = 8MMySQL的随机读缓冲区大小。当按任意顺序读取行时(例如,按照排序顺序),将分配一个随机读缓存区。进行排序查询时,MySQL会首先扫描一遍该缓冲,以避免磁盘搜索,提高查询速度,如果需要排序大量数据,可适当调高该值。但MySQL会为每个客户连接发放该缓冲空间,所以应尽量适当设置该值,以避免内存开销过大sort_buffer_size = 8MMySQL执行排序使用的缓冲大小。如果想要增加ORDER BY的速度,首先看是否可以让MySQL使用索引而不是额外的排序阶段。如果不能,可以尝试增加sort_buffer_size变量的大小join_buffer_size = 8M联合查询操作所能使用的缓冲区大小,和sort_buffer_size一样,该参数对应的分配内存也是每连接独享thread_cache_size = 8这个值(默认8)表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,增加这个值可以改善系统性能.通过比较Connections和Threads_created状态的变量,可以看到这个变量的作用。(–>表示要调整的值)根据物理内存设置规则如下:1G —> 82G —> 163G —> 32大于3G —> 64query_cache_size = 8MMySQL的查询缓冲大小(从4.0.1开始,MySQL提供了查询缓冲机制)使用查询缓冲,MySQL将SELECT语句和查询结果存放在缓冲区中,今后对于同样的SELECT语句(区分大小写),将直接从缓冲区中读取结果。根据MySQL用户手册,使用查询缓冲最多可以达到238%的效率。通过检查状态值'Qcache_%',可以知道query_cache_size设置是否合理:如果Qcache_lowmem_prunes的值非常大,则表明经常出现缓冲不够的情况,如果Qcache_hits的值也非常大,则表明查询缓冲使用非常频繁,此时需要增加缓冲大小;如果Qcache_hits的值不大,则表明你的查询重复率很低,这种情况下使用查询缓冲反而会影响效率,那么可以考虑不用查询缓冲。此外,在SELECT语句中加入SQL_NO_CACHE可以明确表示不使用查询缓冲query_cache_limit = 2M指定单个查询能够使用的缓冲区大小,默认1Mkey_buffer_size = 4M指定用于索引的缓冲区大小,增加它可得到更好处理的索引(对所有读和多重写),到你能负担得起那样多。如果你使它太大,系统将开始换页并且真的变慢了。对于内存在4GB左右的服务器该参数可设置为384M或512M。通过检查状态值Key_read_requests和Key_reads,可以知道key_buffer_size设置是否合理。比例key_reads/key_read_requests应该尽可能的低,至少是1:100,1:1000更好(上述状态值可以使用SHOW STATUS LIKE 'key_read%'获得)。注意:该参数值设置的过大反而会是服务器整体效率降低ft_min_word_len = 4分词词汇最小长度,默认4如下transaction_isolation = REPEATABLE-READMySQL支持4种事务隔离级别,他们分别是:READ-UNCOMMITTED, READ-COMMITTED, REPEATABLE-READ, SERIALIZABLE.如没有指定,MySQL默认采用的是REPEATABLE-READ,ORACLE默认的是READ-COMMITTEDlog_bin = mysql-binbinlog_format = mixedexpire_logs_days = 30 #超过30天的binlog删除log_error = /data/mysql/mysql-error.log #错误日志路径slow_query_log = 1long_query_time = 1 #慢查询时间 超过1秒则为慢查询slow_query_log_file = /data/mysql/mysql-slow.logperformance_schema = 0explicit_defaults_for_timestamplower_case_table_names = 1 #不区分大小写skip-external-locking #MySQL选项以避免外部锁定。该选项默认开启default-storage-engine = InnoDB #默认存储引擎innodb_file_per_table = 1InnoDB为独立表空间模式,每个数据库的每个表都会生成一个数据空间独立表空间优点:1.每个表都有自已独立的表空间。2.每个表的数据和索引都会存在自已的表空间中。3.可以实现单表在不同的数据库中移动。4.空间可以回收(除drop table操作处,表空不能自已回收)缺点:单表增加过大,如超过100G结论:共享表空间在Insert操作上少有优势。其它都没独立表空间表现好。当启用独立表空间时,请合理调整:innodb_open_filesinnodb_open_files = 500限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。这个值默认是300innodb_buffer_pool_size = 64MInnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的80%不要设置过大,否则,由于物理内存的竞争可能导致操作系统的换页颠簸.注意在32位系统上你每个进程可能被限制在 2-3.5G 用户层面内存限制,所以不要设置的太高.innodb_write_io_threads = 4innodb_read_io_threads = 4innodb使用后台线程处理数据页上的读写 I/O(输入输出)请求,根据你的 CPU 核数来更改,默认是4注:这两个参数不支持动态改变,需要把该参数加入到my.cnf里,修改完后重启MySQL服务,允许值的范围从 1-64innodb_thread_concurrency = 0默认设置为 0,表示不限制并发数,这里推荐设置为0,更好去发挥CPU多核处理能力,提高并发量innodb_purge_threads = 1InnoDB中的清除操作是一类定期回收无用数据的操作。在之前的几个版本中,清除操作是主线程的一部分,这意味着运行时它可能会堵塞其它的数据库操作。从MySQL5.5.X版本开始,该操作运行于独立的线程中,并支持更多的并发数。用户可通过设置innodb_purge_threads配置参数来选择清除操作是否使用单独线程,默认情况下参数设置为0(不使用单独线程),设置为 1 时表示使用单独的清除线程。建议为1innodb_flush_log_at_trx_commit = 20:如果innodb_flush_log_at_trx_commit的值为0,log buffer每秒就会被刷写日志文件到磁盘,提交事务的时候不做任何操作(执行是由mysql的master thread线程来执行的。主线程中每秒会将重做日志缓冲写入磁盘的重做日志文件(REDO LOG)中。不论事务是否已经提交)默认的日志文件是ib_logfile0,ib_logfile11:当设为默认值1的时候,每次提交事务的时候,都会将log buffer刷写到日志。2:如果设为2,每次提交事务都会写日志,但并不会执行刷的操作。每秒定时会刷到日志文件。要注意的是,并不能保证100%每秒一定都会刷到磁盘,这要取决于进程的调度。每次事务提交的时候将数据写入事务日志,而这里的写入仅是调用了文件系统的写入操作,而文件系统是有 缓存的,所以这个写入并不能保证数据已经写入到物理磁盘默认值1是为了保证完整的ACID。当然,你可以将这个配置项设为1以外的值来换取更高的性能,但是在系统崩溃的时候,你将会丢失1秒的数据。设为0的话,mysqld进程崩溃的时候,就会丢失最后1秒的事务。设为2,只有在操作系统崩溃或者断电的时候才会丢失最后1秒的数据。InnoDB在做恢复的时候会忽略这个值。总结设为1当然是最安全的,但性能页是最差的(相对其他两个参数而言,但不是不能接受)。如果对数据一致性和完整性要求不高,完全可以设为2,如果只最求性能,例如高并发写的日志服务器,设为0来获得更高性能innodb_log_buffer_size = 2M此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL开发人员建议设置为1-8M之间innodb_log_file_size = 32M此参数确定数据日志文件的大小,更大的设置可以提高性能,但也会增加恢复故障数据库所需的时间innodb_log_files_in_group = 3为提高性能,MySQL可以以循环方式将日志文件写到多个文件。推荐设置为3innodb_max_dirty_pages_pct = 90innodb主线程刷新缓存池中的数据,使脏数据比例小于90%innodb_lock_wait_timeout = 120InnoDB事务在被回滚之前可以等待一个锁定的超时秒数。InnoDB在它自己的锁定表中自动检测事务死锁并且回滚事务。InnoDB用LOCK TABLES语句注意到锁定设置。默认值是50秒bulk_insert_buffer_size = 8M批量插入缓存大小, 这个参数是针对MyISAM存储引擎来说的。适用于在一次性插入100-1000+条记录时, 提高效率。默认值是8M。可以针对数据量的大小,翻倍增加。myisam_sort_buffer_size = 8MMyISAM设置恢复表之时使用的缓冲区的尺寸,当在REPAIR TABLE或用CREATE INDEX创建索引或ALTER TABLE过程中排序 MyISAM索引分配的缓冲区myisam_max_sort_file_size = 10G如果临时文件会变得超过索引,不要使用快速排序索引方法来创建一个索引。注释:这个参数以字节的形式给出myisam_repair_threads = 1如果该值大于1,在Repair by sorting过程中并行创建MyISAM表索引(每个索引在自己的线程内)interactive_timeout = 28800服务器关闭交互式连接前等待活动的秒数。交互式客户端定义为在mysql_real_connect()中使用CLIENT_INTERACTIVE选项的客户端。默认值:28800秒(8小时)wait_timeout = 28800服务器关闭非交互连接之前等待活动的秒数。在线程启动时,根据全局wait_timeout值或全局interactive_timeout值初始化会话wait_timeout值,取决于客户端类型(由mysql_real_connect()的连接选项CLIENT_INTERACTIVE定义)。参数默认值:28800秒(8小时)MySQL服务器所支持的最大连接数是有上限的,因为每个连接的建立都会消耗内存,因此我们希望客户端在连接到MySQL Server处理完相应的操作后,应该断开连接并释放占用的内存。如果你的MySQL Server有大量的闲置连接,他们不仅会白白消耗内存,而且如果连接一直在累加而不断开,最终肯定会达到MySQL Server的连接上限数,这会报'too many connections'的错误。对于wait_timeout的值设定,应该根据系统的运行情况来判断。在系统运行一段时间后,可以通过show processlist命令查看当前系统的连接状态,如果发现有大量的sleep状态的连接进程,则说明该参数设置的过大,可以进行适当的调整小些。要同时设置interactive_timeout和wait_timeout才会生效。[mysqldump]quickmax_allowed_packet = 16M #服务器发送和接受的最大包长度[myisamchk]key_buffer_size = 8Msort_buffer_size = 8Mread_buffer = 4Mwrite_buffer = 4M*
-
如何在Mysql(8.0)下面修改密码 Linux下mysql升级到8.0版本了,以往mysql5.7设置密码的方法已经失效,故各种查资料找方法,寻到mysql8.0root账号密码修改方法。*开始 当我们安装好mysql-8.0后,在root用户下,我们可以直接凭借root的特权直接进入mysql命令行态,但这样我们的服务器极其危险,任何攻击下服务器的不法分子都可以轻轻松松获取它想要的服务数据。那么我们现在就是如何给服务器添加密码1.我们需要重新启动下我们的mysql服务器systemctl rastatus mysql.server2.在root态下。我们进入mysql命令行。use mysql ;切换数据库3.此时输入ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';4.需要先将root密码置空update user set authentication_string='' where user = 'root';然后在执行第3步即可 5.刷新mysql相关系统权限表,退出FLUSH privileges; 好了,新的密码就设置好的